
View
SELECT 절의 처리 순서

위 순서가 바뀌어서 실행되는 형태의 쿼리는 거의 없다.
쿼리에서 어느 절이 먼저 실행되는지 모르면 처리 내용이나 처리 결과를 예측할 수 없으므로 잘 알아두자.
다만, 실행 순서를 벗어나는 쿼리가 필요하다면 서브쿼리로 작성된 인라인 뷰를 사용하면 된다.
인라인 뷰(Inline View)란?
하나의 질의문 내에서만 생성되어 사용 되어지고 질의문 수행 종료 후에는 사라지는 뷰를 뜻한다.
일반적으로 FROM 절에서 서브쿼리를 하나의 테이블로 사용하는 형태를 말한다.
하지만 인라인 뷰가 사용되면 임시 테이블이 사용되기 때문에 주의해야 한다.
WHERE 조건과 GROUP BY 절, ORDER BY 절의 인덱스 사용
인덱스를 사용하기 위한 기본 규칙
인덱스 컬럼 변형 없이 사용하기
WHERE 절이나 ORDER BY, GROUP BY가 인덱스를 사용하려면 값에 대한 변형 없이 인덱스 컬럼을 그대로 사용해야 한다.
SELECT * FROM salaries WHERE salary * 10 > 150000;위와 같은 쿼리는 salary 인덱스가 있더라도 값을 변형해서 비교하므로 인덱스를 이용할 수 없다.
비교 대상의 데이터 타입 일치
WHERE 절에 사용되는 비교 조건에서 연산자 양쪽의 비교 대상 값은 데이터 타입이 일치해야 한다.
SELECT * FROM tb_test WHERE age=2;위 쿼리의 age 컬럼은 문자열 타입으로 선언되었지만 비교 연산에는 숫자 타입으로 비교된다. 따라서 ref나 range가 아닌 index(인덱스 풀 스캔)이 사용된다.
이 경우 MySQL 옵티마이저가 내부적으로 문자열 타입을 숫자 타입으로 변환한 후 비교 작업을 처리하는데, 타입이 변환된 후 비교 작업을 처리해야 하므로 인덱스 레인지 스캔이 불가능한 것이다.
따라서 SQL을 작성할 때는 반드시 데이터 타입을 맞춰 비교 조건을 사용하자.
WHERE 절의 인덱스 사용
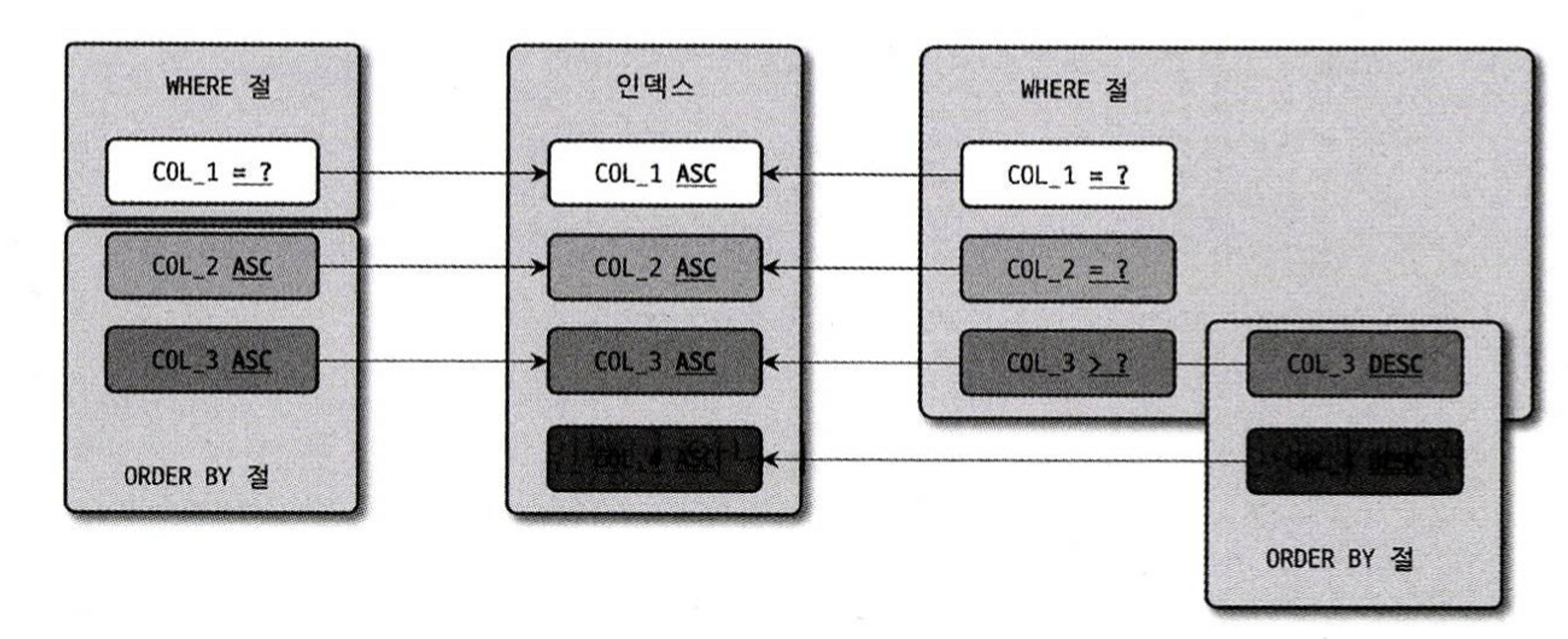
WHERE 절의 인덱스 사용 방법은 작업 범위 결정 조건과 체크 조건 두 가지 방식으로 구분한다.
작업 범위 결정 조건은 동등 비교 조건이나 IN으로 구성된 조건에 사용된 컬럼들이 인덱스의 구성과 좌측부터 얼마나 일치하는가에 따라 달라진다.
위 그림에서 WHERE 조건절의 순서는 실제 인덱스의 사용 여부와 무관하다.
옵티마이저는 인덱스를 사용할 수 있는 조건을 뽑아서 최적화를 수행할 수 있기 때문이다.
WHERE 조건절에서 COL_1과 COL_2는 동등 비교 조건이고 COL_3은 범위 비교 조건이다.
따라서 그 뒤 컬럼인 COL_4는 인덱스의 범위 결정 조건으로 사용되지 못하고 체크 조건으로 사용된다.
다중 컬럼 인덱스에서는 N-1번째 컬럼이 N번째 컬럼에 의존해 다시 정렬된다. 즉, COL_3 컬럼까지는 비교 작업의 범위를 줄이는데(작업 범위 결정 조건) 도움을 주지만 COL_4 컬럼은 COL_3에 의존적이므로 범위를 좁히지 못하고 단순히 비교 용도(필터링 조건)로만 사용되어 체크 조건으로 사용되는 것이다.
위 예시들은 모두 AND 조건으로 연결되는 경우를 가정한 것이며, OR 조건으로 묶이면 더욱 복잡해진다.
OR로 연결되면 읽어서 비교해야 할 레코드가 더 늘어나기 때문에 주의해야한다.
GROUP BY 절의 인덱스 사용
GROUP BY 절의 각 컬럼은 비교 연산자를 가지지 않으므로 작업 범위 결정 조건이나 체크 조건을 구분해서 생각할 필요 없이 GROUP BY 절에 명시된 컬럼의 순서가 인덱스 구성 컬럼 순서와 동일하면 인덱스를 이용할 수 있다.
- GROUP BY 인덱스 사용 조건
- GROUP BY 절에 명시된 컬럼이 인덱스 컬럼의 순서와 같아야 한다.
- 순서상 인덱스의 앞쪽에 있는 컬럼이 GROUP BY 절에 명시되지 않으면 인덱스를 사용할 수 없다.
- GROUP BY 절에 명시된 컬럼이 하나라도 인덱스에 없으면 인덱스를 사용하지 못한다.
WHERE 절과 GROUP BY 절이 혼용된 쿼리가 인덱스를 사용할 수 있는지를 판별하기 위해서는 WHERE 절에서 동등 비교 조건으로 사용된 컬럼을 GROUP BY 절로 옮겨보자.
- // 원본 쿼리
... WHERE COL_1 ='상수' ... GROUP BY COL_2, COL_3
— // WHERE 조건절의 COL_1 칼럼을 GROUP BY 절의 앞쪽으로 포함시켜 본 쿼리
... WHERE COL_1 ='상수' ... GROUP BY COL_1, COL_2, COL_3위와 같이 변경해도 똑같은 결과가 조회된다면 인덱스를 사용할 수 있는 쿼리로 판단하면 된다.
ORDER BY 절의 인덱스 사용
ORDER BY와 GROUP BY는 처리 방법이 거의 비슷하다. 따라서 인덱스 사용 조건도 거의 흡사하다.
한 가지 다른 점이 있다면, 정렬되는 컬럼의 오름차순 및 내림차순 옵션이 인덱스와 같거나 정반대인 경우에만 사용할 수 있다는 것이다.
WHERE 조건과 ORDER BY(또는 GROUP BY) 절의 인덱스 사용
우리가 사용하는 쿼리는 일반적으로 WHERE 절과 GROUP BY 절, ORDER BY 절 등을 포함한 복잡한 형태의 쿼리로 구성된다.
하나의 쿼리에는 하나의 인덱스만 사용 가능하므로(index_merge 제외) 여러 개의 절이 같이 사용된 쿼리 문장은 다음 3가지 중 한 가지 방법으로만 인덱스를 이용한다.
- WHERE 절과 ORDER BY 절이 동시에 같은 인덱스를 사용
- WHERE 절의 비교 조건과 ORDER BY 절의 정렬 대상이 모두 하나의 인덱스에 연속해서 포함돼 있을 때 사용 가능
- 가장 빠른 성능을 보이므로 이 방식으로 처리될 수 있도록 튜닝하거나 인덱스를 생성하는 것이 좋음
- WHERE 절만 인덱스 사용
- ORDER BY 절은 인덱스를 통해 검색된 레코드를 별도 정렬 처리 과정(Using Filesort)으로 처리
- WHERE 조건절에 일치하는 레코드 건수가 많지 않을 때 효율적인 방식(레코드 건수가 많은 경우 Using Filesort가 부하를 유발)
- ORDER BY 절만 인덱스를 사용
- ORDER BY 절의 순서대로 인덱스를 읽으며 WHERE 절의 조건에 일치하는지 비교하는 형태
- 대량의 레코드를 조회해서 정렬해야 할 때 이런 형태로 튜닝
이 방식도 마찬가지로 WHERE 절에 동등 비교로 비교된 컬럼과 ORDER BY 절에 명시된 컬럼이 순서대로 빠짐없이 인덱스에 왼쪽부터 일치해야 한다. 그렇지 않다면 역시 인덱스를 사용할 수 없다.
이제 범위 조건 비교가 사용되는 쿼리 예제를 살펴보자.
SELECT * FROM tb.test WHERE COL_1 > 10 ORDER BY COL_1, COL_2, COL_3;위 쿼리에서 COL_1에 만족하는 값은 여러 개일 수 있지만 ORDER BY 절에서 인덱스가 순서대로 모두 명시되었기 때문에 인덱스를 사용할 수 있다.
하지만 다음과 같은 경우 인덱스를 이용하지 못한다.
SELECT * FROM tb.test WHERE COL_1 > 10 ORDER BY COL_2, COL_3;COL_1이 동등 비교 조건이었다면 인덱스를 사용할 수 있었겠지만, 범위 조건이므로 ORDER BY 절에서 COL_1이 명시되지 않은 이 쿼리는 인덱스를 이용하지 못한다.
GROUP BY 절과 ORDER BY 절의 인덱스 사용
두 절이 모두 하나의 인덱스를 사용해서 처리되려면 GROUP BY 절과 ORDER BY 절에 명시된 컬럼의 순서와 내용이 모두 같아야 한다.
따라서 둘 중 하나라도 인덱스를 사용할 수 없는 경우 두 절 모두에서 인덱스를 사용할 수 없다.
-- // 인덱스 사용 불가
... GROUP BY col_1, col_2 ORDER BY col_2
... GROUP BY col_1, col_2 ORDER BY col_1, col_3MySQL 5.7 버전까지는 GROUP BY 컬럼에 대한 정렬까지 함께 수행하는 것이 기본 작동 방식이지만, MySQL 8.0 버전부터는 GROUP BY 컬럼의 정렬까지 보장하지 않는 형태로 변경되었다.
WHERE 조건과 ORDER BY 절, GROUP BY 절의 인덱스 사용
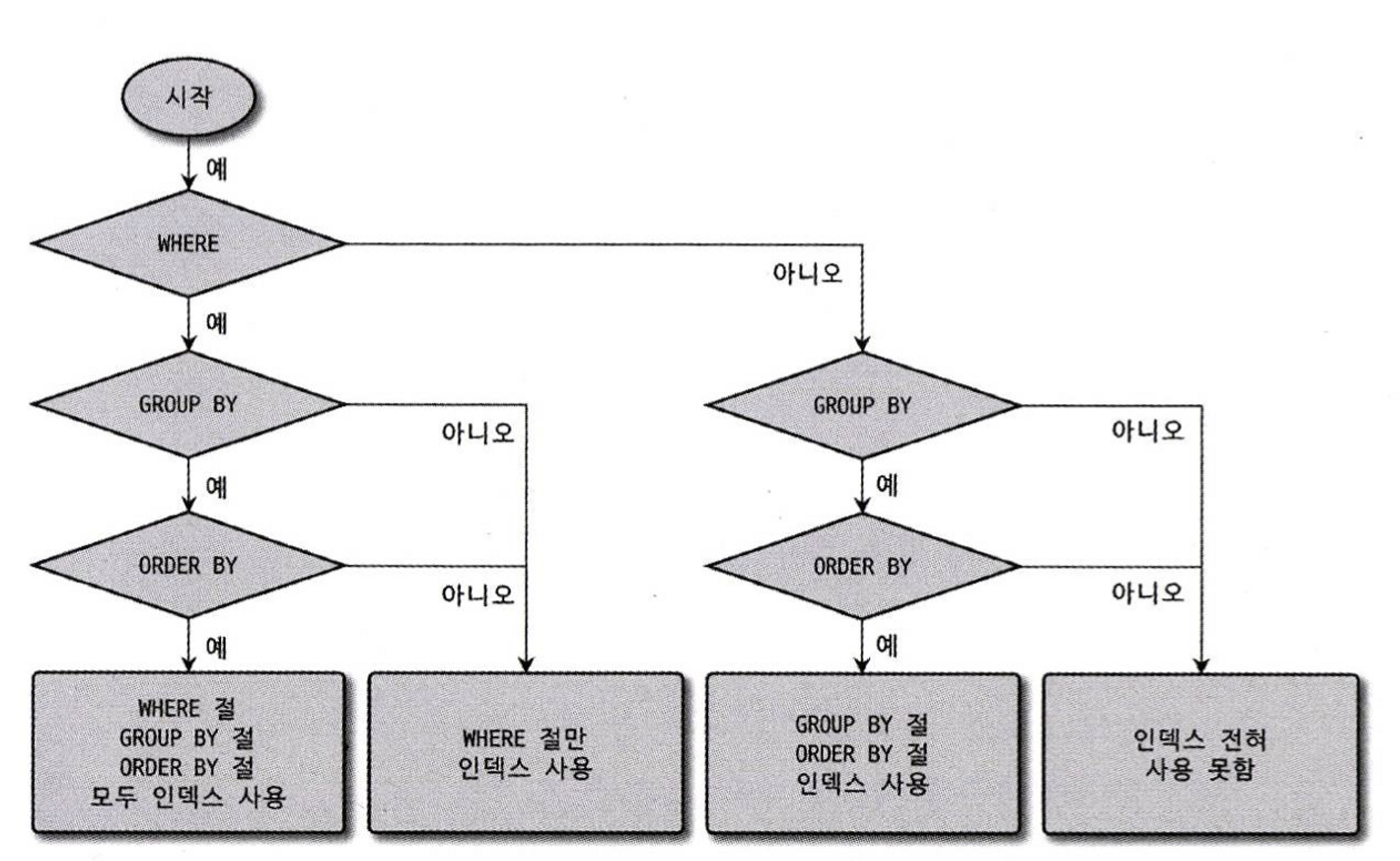
WHERE, GROUP BY, ORDER BY 절이 모두 포함된 쿼리가 인덱스를 사용하는지 판단하기 위해서 다음 흐름도를 적용해보자.
- WHERE 절이 인덱스를 사용할 수 있는가?
- GROUP BY 절이 인덱스를 사용할 수 있는가?
- GROUP BY 절과 ORDER BY 절이 동시에 인덱스를 사용할 수 있는가?
WHERE 절의 비교 조건 사용 시 주의사항
NULL 비교
MySQL에서는 NULL 값이 포함된 레코드도 인덱스로 관리한다.
SELECT * FROM titles WHERE to_date IS NULL;
+----+-------+-----+----------+-------------------------+
| id | table |type |key |Extra |
+----+-------+-----+----------+-------------------------+
| 1 | titles|ref |ix_todate | Using where;Using index |
+----+-------+-----+----------+-------------------------+위 쿼리의 실행계획에서 to_date 컬럼이 NULL인 레코드를 조회하는 쿼리지만 인덱스를 ref 방식으로 적절히 사용하고 있음을 알 수 있다.
컬럼의 값이 NULL인지 확인할 때는 ISNULL() 함수를 사용해도 되지만, 가급적 IS NULL 연산자를 사용하는 것을 권장한다. ISNULL() 함수를 사용한 다음과 같은 쿼리 형태의 경우 인덱스를 사용하지 못하기 때문이다.
SELECT * FROM titles WHERE ISNULL(to_date)=1;
SELECT * FROM titles WHERE ISNULL(to_date)=true;
문자열이나 숫자 비교
문자열 컬럼이나 숫자 컬럼을 비교할 때는 반드시 그 타입에 맞는 상수값을 사용해야 한다. 컬럼의 타입에 맞게 상수 리터럴을 비교 조건에 사용하는 것은 인덱스 사용 여부에도 영향을 미치므로 아주 중요하다.
날짜 비교
MySQL에는 날짜만 저장하는 DATE 타입과 날짜와 시간을 함께 저장하는 DATETIME과 TIMESTAMP 타입이 있으며, 시간만 저장하는 TIME 타입도 있기 때문에 각 비교 조건들이 상당히 헷갈릴 수 있다.
DATE 또는 DATETIME과 문자열 비교
DATE 또는 DATETIME 타입의 값과 문자열을 비교할 때는 문자열 값을 자동으로 DATETIME 타입의 값으로 변환해서 비교를 수행한다. 문자열을 DATE나 DATETIME 타입으로 명시적으로 변환하지 않아도 MySQL이 내부적으로 변환을 수행한다.
가끔씩 아래와 같이 DATE나 DATETIME 타입의 컬럼을 문자열로 변경하는 경우가 있는데, 이는 인덱스를 효율적으로 사용할 수 없으니 가능하면 컬럼을 변경하지 말고 상수를 변경하는 형태로 조건을 사용하는 것이 좋다.
-- // 인덱스 사용 X
SELECT COUNT(*) FROM employees
WHERE DATE_FORMAT(hire_date,'%Y-%m-%d') > '2011-07-23' ;또한, 날짜 타입 컬럼의 값을 더하거나 빼는 함수로 변형한 후 비교해도 인덱스를 사용할 수 없다.
-- // 인덱스 사용 X
SELECT COUNT(*) FROM employees
WHERE DATE_ADD(hire_date, INTERVAL 1 YEAR) > '2011-07-23' ;
-- // 인덱스 사용 O -> 상수를 변경하는 형태 권장
SELECT COUNT(*) FROM employees
WHERE hire_date > DATE_SUB('2011-07-23', INTERVAL 1 YEAR);
DATE와 DATETIME의 비교
DATETIME 값을 DATE 타입으로 만들지 않고 비교하면 MySQL 서버가 DATE 타입의 값을 DATETIME으로 변환해서 비교를 수행한다.
즉, DATE 타입인 “2022-11-19” 값을 DATETIME 타입인 “2022-11-19 00:00:00”으로 변환해서 비교를 수행한다. 따라서 DATE와 DATETIME을 비교할 때는 성능보다는 쿼리 결과에 주의해서 사용해야 한다.
DATETIME과 TIMESTAMP의 비교
DATE 혹은 DATETIME 타입 값과 TIMESTAMP의 값을 별도 타입 변환 없이 비교하면 원하는 결괏값을 얻을 수 없다. 반드시 비교 값으로 사용되는 상수 리터럴을 비교 대상 컬럼의 타입으로 변환해서 사용하는 것이 좋다.
DATETIME 타입이라면 FROM_UNIXTIME() 함수를 이용해 DATETIME 타입으로 만들어 비교해야 한다. 반대로 TIMESTAMP라면 UNIX_TIMESTAMP() 함수를 이용해 DATETIME을 TIMESTAMP로 변환해 비교해야 한다.
- FROM_UNIXTIME()
- TIMESTAMP → DATETIME
- UNIX_TIMESTAMP()
- DATETIME → TIMESTAMP
Short-Circuit Evaluation
Short-circuit Evaluation이란 여러 개의 표현식이 AND 또는 OR 연산자로 연결된 경우 선행 표현식의 결과에 따라 뒤에 연산을 평가할지 말지 결정하는 최적화를 말한다.
예를 들어, 다음과 같은 표현식이 있다고 가정해보자.
if (isMember() && hasName()) {
....
}isMember() 함수가 True를 반환한다면 후행 표현식인 hasName() 함수를 호출해 결과를 확인해야 한다. 하지만 isMember() 함수가 False를 반환한다면 hasName()을 검사할 필요가 없다. 후행 표현식을 확인하지 않아도 결과는 False를 반환하기 때문이다.
Short-circuit Evaluation는 쿼리 성능에 영향을 준다.
WHERE 조건절에 명시된 조건이 인덱스를 사용할 수 없는 경우 순서에 따라 조회하는 레코드 건수가 달라질 수 있기 때문이다.
다음과 같은 결과를 반환하는 쿼리를 살펴보자.
두 쿼리 모두 인덱스를 사용하지 못하고 풀 테이블 스캔을 사용한다고 가정한다.
-- // 1번 조건을 만족하는 레코드 건수
SELECT COUNT(*) FROM salaries
WHERE CONVERT_TZ(from_date,'+00:00', '+09:00') > '1991-01-01';
+----------+
| COUNT(*) |
+----------+
| 2442943 |
+----------+
-- // 2번 조건을 만족하는 레코드 건수
SELECT COUNT(*) FROM salaries
WHERE to_date < '1985-01-01' ;
+----------+
| COUNT(*) |
+----------+
| 0 |
+----------+이제 위의 두 쿼리를 하나의 쿼리로 조합하고 WHERE 조건의 순서만 변경해서 결과를 살펴보자.
-- // (1번 조건, 2번 조건) 순으로 조합
SELECT * FROM salaries
WHERE CONVERT_TZ(from_date,'+00:00', '+09:00') > '1991-01-01'
AND to_date < '1985-01-01';
==> (0.73 sec)
-- // (2번 조건, 1번 조건) 순으로 조합
SELECT * FROM salaries
WHERE to_date < '1985-01-01'
AND CONVERT_TZ(from_date,'+00:00', '+09:00') > '1991-01-01';
==> (0.52 sec)확실히 성능에 차이가 있는 걸 확인할 수 있다.
현재는 근소한 차이지만 만약 더 많은 자원을 소모하는 조건이었다면 성능 차이는 더욱 커졌을 것이다.
이처럼 MySQL 서버는 쿼리의 WHERE 절에 나열된 조건을 순서대로 Short-circuit Evaluation 방식으로 평가해 레코드를 반환할지 말지를 결정한다.
하지만 WHERE 절의 조건 중 인덱스를 사용할 수 있는 조건이 있다면 MySQL 서버는 그 조건을 최우선으로 사용하며, 나열된 조건의 순서가 인덱스 사용 여부를 결정하지는 않는다.
MySQL 서버에서 쿼리를 작성할 때 가능하면 복잡한 연산 또는 다른 테이블의 레코드를 읽어야 하는 서브쿼리 조건 등은 WHERE 절의 뒤쪽으로 배치하는 것이 성능상 도움이 된다는 것을 알아두자.
DISTINCT
LIMIT n
LIMIT는 쿼리 결과에서 지정된 순서에 위치한 레코드만 가져오고자 할 때 사용한다.
일반적으로 MySQL 서버에서 LIMIT는 쿼리의 가장 마지막에 실행된다. 따라서 GROUP BY 절이나 DISTINCT 등과 같이 사용됐을 때 어떻게 동작하는지 알아둘 필요가 있다.
SELECT * FROM employees LIMIT 0, 10;- 해당 쿼리는 풀 테이블 스캔을 하면서 10개의 레코드를 읽어 들인 시점에 읽기 작업을 멈춘다.
- 이러한 형태의 쿼리는 LIMIT를 이용해 쿼리를 상당히 빨리 끝낼 수 있다.
SELECT * FROM employees GROUP BY first_name LIMIT 0, 10;- 해당 쿼리는 GROUP BY 처리가 완료되고 LIMIT 처리를 수행한다.
- 따라서 LIMIT가 실질적 서버 작업을 크게 줄여주지 못한다.
SELECT DISTINCT first_name FROM employees LIMIT 0, 10;- 해당 쿼리는 중복 제거 작업(DISTINCT)을 반복 처리하다 유니크한 레코드가 10건 채워지면 작업을 중지한다.
- LIMIT 절을 활용해 작업량을 상당히 줄인 쿼리다.
LIMIT 주의 사항
- LIMIT의 인자로 표현식이나 별도의 서브쿼리를 사용할 수 없다.
SELECT * FROM employees LIMIT (100-10) ;
ERROR 1064 (42000) :You have an error in your SQL syntax;check the manual that corresponds to your MySQL server version for the right syntax to use near '(100-10)' at line 1- 페이징 처리
SELECT * FROM salaries ORDER BY salary LIMIT 0,10;
10 rows in set (0.00 sec)
SELECT * FROM salaries ORDER BY salary LIMIT 2000000,10;
10 rows in set (1.57 sec)이 경우 10건의 레코드를 가져오는 결과는 같지만 MySQL 서버가 처리하는 작업 내용이 다르다.
아래 쿼리의 경우 2,000,010건의 레코드를 읽은 후 2,000,000건은 버리고 마지막 10건만 사용자에게 반환한다. 이러한 비효율을 막기 위해서는 다음과 같이 WHERE 조건절로 읽어야 할 위치를 찾고 그 위치에서 10건만 반환하도록 쿼리를 변경하는 것이 좋다.
SELECT * FROM salaries
WHERE salary >= 154888 AND NOT(salary=154888 AND emp_no <= 109334)
ORDER BY salary LIMIT 0, 10;위 예제에서NOT(salary=154888 AND emp_no <= 109334) 조건을 명시한 이유는 중복이나 누락을 방지하기 위함이다.
중복을 허용하는 인덱스를 사용하는 경우 단순히 이전 페이지의 마지막 값보다 큰 값을 조회하거나 크거나 같은 경우를 조회하면 중복이나 누락이 발생할 수 있기 때문이다. 페이징을 위한 쿼리 작성 시 주의해야 할 부분이다.
COUNT()
COUNT() 함수는 결과 레코드의 건수를 반환하는 함수다.
InnoDB 스토리지 엔진에서는 WHERE 조건이 없는 COUNT(*) 쿼리라고 해도 데이터나 인덱스를 읽어야 레코드 건수를 가져올 수 있다. 따라서 큰 테이블에서 COUNT() 함수를 사용할 때는 주의를 기울어야 한다.
주의 사항
- ORDER BY나 LEFT JOIN과 같은 레코드 건수를 가져오는 것과 무관한 작업을 포함
- COUNT(*) 쿼리에 ORDER BY 절은 어떤 경우에도 필요하지 않다.
또한, LEFT JOIN도 레코드 건수의 변화가 없는 경우나 아우터 테이블에서 별도 체크를 하지 않아도 된다면 제거하는 것이 성능상 좋다.
- COUNT(*) 쿼리에 ORDER BY 절은 어떤 경우에도 필요하지 않다.
- 인덱스를 사용하지 못하는 경우
- 페이징해서 데이터를 가져오는 것보다 몇 배 ~ 몇십 배 느리게 실행될 수 있다.
- 레코드의 결과가 NULL이 아닌 레코드 건수만 반환
- NULL이 될 수 있는 컬럼은 의도대로 작동하지 않을 수 있다.
'BackEnd > Real MySQL 8.0' 카테고리의 다른 글
| [Real MySQL 8.0] 실행 계획 분석하기(Extra) (0) | 2022.11.10 |
|---|---|
| [Real MySQL 8.0] 실행 계획 분석하기(type ~ filtered) (0) | 2022.10.23 |
| [Real MySQL 8.0] 실행 계획 분석하기(id ~ partitions) (0) | 2022.10.19 |
| [Real MySQL 8.0] 실행 계획 통계 정보와 실행 계획을 확인하는 방법 (0) | 2022.10.05 |
| [Real MySQL 8.0] 쿼리 힌트 (0) | 2022.09.09 |