
View
InnoDB 스토리지 엔진
MySQL의 스토리지 엔진 중에서 유일하게 레코드 기반의 잠금을 제공하며, 높은 동시성 처리가 가능하고 안정적이며 성능이 뛰어난 스토리지 엔진이다.

프라이머리 키에 의한 클러스터링
- InnoDB의 모든 테이블은 프라이머리 키 값의 순서대로 디스크에 저장된다.
- 모든 세컨더리 인덱스는 레코드 주소 대신 프라이머리 키의 값을 논리적인 주소로 사용한다.
- 프라이머리 키는 클러스터링 인덱스이기 때문에 프라이머리 키를 이용한 레인지 스캔은 상당히 빨리 처리될 수 있다.
- 결과 적으로 쿼리의 실행 계획에서 다른 보조 인덱스보다 프라이머리 키가 인덱스로 선택될 확률이 높다.
외래키 지원
- InnoDB 스토리지 엔진 레벨에서만 지원한다. MyISAM이나 MEMORY 테이블에서는 사용할 수 없다.
- 외래키는 실제 서비스 운영 환경에 사용하지 않는 경우가 있다. 그 이유는 부모와 자식 테이블에 인덱스 생성이 필요하고, 변경 시 잠금이 여러 테이블로 전파되어 데드락이 발생할 확률이 높아지기 때문이다.
- foreign_key_checks 시스템 변수를 OFF로 설정하여 외래키 관계 체크 작업을 일시적으로 멈출 수 있다.
- foreign_key_checks 시스템 변수를 OFF한 경우 데이터 일관성에 문제가 생길 수 있으므로 반드시 부모와 자식 테이블 간 일관성을 맞춘 후 다시 활성화해야 한다.
MVCC(Multi Version Concurrency Control)
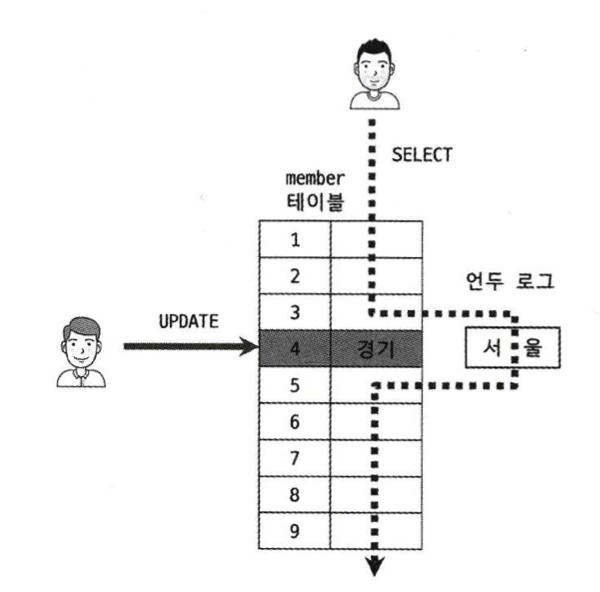
MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는데 있다. InnoDB 스토리지 엔진은 언두 로그를 이용해 MVCC 기능을 구현했다.
MVCC는 하나의 레코드에 대해 여러 버전이 동시에 관리되는 것을 뜻하며 격리 수준(isolation level)에 따라 처리되는 방식이 다르다.
READ_UNCOMMITTED의 경우 InnoDB 버퍼 풀이나 데이터 파일로부터 데이터를 읽어 반환한다. 즉, 커밋됐든 아니든 변경된 상태의 데이터를 반환하게 된다. 그 이상의 격리 수준인 READ_COMMITTED, REPEATABLE_READ은 InooDB 버퍼 풀이나 데이터 파일 대신 변경되기 전 내용을 보관하고 있는 언두 영역의 데이터를 반환하며, 이러한 과정을 MVCC라고 표현한다.
잠금 없는 일관된 읽기
InnoDB 스토리지 엔진은 MVCC을 이용해 잠금을 걸지 않고 읽기 작업을 수행한다.
SERIALIZABLE이 아닌 다른 격리 수준에서는 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고 읽기 작업이 가능하다.
자동 데드락 감지
- InnoDB 스토리지 엔진은 잠금 대기 목록을 그래프 형태로 관리한다.
- 데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션을 강제 종료한다.
- 언두 로그의 양이 적은 트랜잭션이 먼저 종료된다.
데드락 감지 스레드가 잠금 목록을 체크할 때 잠금 목록에 새로운 잠금이 걸리므로 동시 처리 스레드가 매우 많은 경우 많은 CPU 자원 소모가 생길 수 있다. 따라서 서비스에 성능에 악영향을 줄 수 있는 상황이 생긴다.
이 문제를 해결하는 방법 중 하나는 innodb_deadlock_detect 시스템 변수를 OFF 하고 innodb_lock_wait_timeout 시스템 변수를 활성화하여 데드락 상황에서 일정 시간 동안 잠금을 획득하지 못했을 경우 요청이 실패하고 에러 메시지를 반환하게 하는 방식으로 문제를 우회할 수 있다.
자동화된 장애 복구
InnoDB는 손실이나 장애로부터 데이터를 보호하기 위한 여러 메커니즘이 탑재되어 있다.
InnoDB 데이터 파일은 기본적으로 MySQL 서버가 시작될 때 항상 자동 복구를 수행하는데, 디스크나 서버 하드웨어 이슈로 자동 복구를 못하는 경우가 발생하면 자동 복구를 멈추고 MySQL 서버가 종료돼 버린다.
이때는 innodb_force_recovery 시스템 변수를 설정해서 MySQL 서버를 시작해야 한다.
1~6의 값을 가지며 단계 별로 선별적 자동복구를 진행할 수 있다.
- innodb_force_recovery - 1 (SRV_FORCE_IGNORE_CORRUPT)
- InnoDB의 테이블스페이스의 데이터나 인덱스 페이지에서 손상된 부분이 발견돼도 무시하고 MySQL 서버를 시작한다.
- innodb_force_recovery - 2 (SRV_FORCE_NO_BACKGROUND)
- 백그라운드 스레드 가운데 메인 스레드를 시작하지 않고 MySQL 서버를 시작한다. InnoDB의 메인 스레드가 언두 데이터를 삭제하는 과정에서 장애가 발생한다면 이 모드로 복구하면 된다.
- innodb_force_recovery - 3 (SRV_FORCE_NO_TRX_UNDO)
- 커밋되지 않고 종료된 트랜잭션은 계속 그 상태로 남아 있게 MySQL 서버를 시작하는 모드
- innodb_force_recovery - 4 (SRV_FORCE_NO_IBUF_MERGE)
- InnoDB 스토리지 엔진이 인서트 버퍼의 내용을 무시하고 강제로 MySQL이 시작되게 한다. 인서트 버퍼는 실제 데이터와 관련된 부분이 아니라 인덱스에 관련된 부분이므로 테이블을 덤프 한 후 다시 데이터베이스를 구축하면 데이터의 손실 없이 복구할 수 있다.
- innodb_force_recovery - 5 (SRV_FORCE_NO_UNDO_LOG_SCAN)
- InnoDB 엔진이 언두 로그를 모두 무시하고 MySQL을 시작할 수 있다. 하지만 이 모드로 복구되면 MySQL 서버가 종료되던 시점에 커밋되지 않았던 작업도 모두 커밋된 것처럼 처리되므로 실제로는 잘못된 데이터가 데이터베이스에 남는 것이라고 볼 수 있다.
- innodb_force_recovery - 6 (SRV_FORCE_NO_LOG_REDO)
- InnoDB 엔진이 리두 로그를 모두 무시한 채로 MySQL 서버가 시작된다. 커밋됐다 하더라도 리두 로그에만 기록되고 데이터 파일에 기록되지 않은 데이터는 모두 무시된다. 즉, 마지막 체크포인트 시점의 데이터만 남게 된다.
InnoDB 버퍼 풀
InnoDB 스토리지 엔진에서 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다. 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 같이 한다.
버퍼 역할?
Insert, Update, Delete처럼 데이터를 변경하는 쿼리는 데이터 파일의 이곳저곳에 위치한 레코드를 변경하기 때문에 랜덤한 디스크 작업을 발생시킨다. 하지만 버퍼 풀이 이러한 변경된 데이터를 모아서 처리하면 랜덤한 디스크 작업의 횟수를 줄일 수 있다.
버퍼 풀의 구조
버퍼 풀이라는 메모리 공간은 페이지라는 조각으로 쪼개지고 필요로 할 때 데이터 페이지를 읽어 각 조각에 저장되는 구조를 가지고 있다.
InnoDB 스토리지 엔진은 버퍼 풀의 페이지 조각을 관리하기 위해 LRU 리스트, 플러시 리스트, 프리 리스트라는 3개의 자료 구조를 관리한다.
- LRU(Least Recently Used) 리스트
- 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀 메모리에 유지해서 디스크 읽기를 최소화
- 플러시 리스트
- 디스크로 동기화되지 않은 데이터 페이지(더티 페이지)의 변경 시점 기준의 페이지 목록을 관리
- 프리 리스트
- 데이터가 채워지지 않은 비어있는 페이지 목록으로, 새롭게 디스크의 데이터 페이지를 읽어와야 하는 경우 사용된다.
버퍼 풀과 리두 로그
InnoDB 버퍼 풀은 데이터베이스 성능 향상을 위해 데이터 캐시 기능과 쓰기 버퍼링 기능을 지원하는데, 버퍼 풀의 메모리 공간을 늘리는 것은 데이터 캐시 기능만 향상시키는 것이다. 쓰기 버퍼링 기능까지 향상시키려면 리두 로그와의 관계를 먼저 이해해야 한다.

InnoDB 버퍼 풀과 리두 로그의 관계 설명의 흐름을 요약해보면 다음과 같다.
- InnoDB 버퍼 풀은 클린 페이지와 더티 페이지(변경된 데이터)를 가진다.
- 더티 페이지는 언젠가 디스크에 기록되어야 한다.
- 한정된 메모리 공간인 버퍼 풀에 더티 페이지가 계속 머무를 수 없으므로 리두 로그 파일과의 순환 고리를 이용해 데이터 변경을 기록한다.
- 리두 로그 파일에 데이터 변경이 기록될 때마다 LSN이라는 시퀀스 번호를 증가시킨다.
- InnoDB 스토리지 엔진은 주기적으로 체크포인트 이벤트를 발생시켜 그 시점의 리두 로그 파일의 LSN을 시작점으로 삼는다.(마지막 LSN은 계속 증가하며 데이터 변경을 기록)
- 체크포인트가 발생하면 LSN 시작점부터 그보다 작은 LSN을 가진 리두 로그 엔트리와 관련된 버퍼 풀의 더티 페이지를 디스크로 동기화한다.
이렇듯, 버퍼 풀의 더티 페이지 비율과 리두 로그 파일의 전체 크기는 쓰기 버퍼링 기능 성능에 관계되어 있다. 따라서 우리가 데이터베이스 성능을 최적화하고 싶다면 InnoDB 버퍼 풀과 리두 로그 파일의 전체 크기를 적절히 선택해 최적 값을 찾아야 한다.
버퍼 풀 상태 백업 및 복구
InnoDB 서버의 버퍼 풀은 쿼리 성능에 밀접한 관계가 있다. 버퍼 풀에 쿼리들이 사용한 데이터가 이미 준비돼 있으므로 디스크에서 데이터를 읽지 않아도 되기 때문에 쿼리 성능이 상당히 올라가게 된다.
쿼리 요청이 매우 빈번한 서버를 재시작하면 성능이 저하되는 것을 볼 수 있는데, 이는 버퍼 풀에 데이터가 올라가 있지 않아서 모든 데이터를 디스크로부터 읽어와야 하기 때문에 발생하는 성능 저하이다.
따라서 MySQL 5.5 버전에서는 서버 시작 전 주요 테이블과 인덱스에 대해 풀 스캔을 실행하고 서비스를 오픈했었다. 하지만 MySQL 5.6 버전부터는 버퍼 풀 덤프 및 적재 기능이 도입되어 innodb_buffer_pool_dump_now 시스템 변수를 이용해 현재 버퍼 풀의 상태를 백업할 수 있게 됐다.
Double Write Buffer
리두 로그는 리두 로그 공간의 낭비를 막기 위해 페이지의 변경된 내용만 기록한다. 하드웨어의 오작동이나 시스템 비정상 종료 등의 문제로 인해 InnoDB 스토리지 엔진에서 더티 페이지를 디스크 파일로 플러시할 때 일부만 기록되는 문제(파셜 페이지 또는 톤 페이지)가 발생하면 그 페이지에 대한 내용을 복구할 수 없을 수도 있다.
DB 스토리지 엔진에서는 Double-Write 기법을 사용해 이러한 문제를 해결한다.

- 실제 데이터 파일에 변경 내용을 기록하기 전에 더티 페이지를 묶어 시스템 테이블스페이스의 DoubleWrite 버퍼에 기록한다.
- InnoDB 스토리지 엔진은 각 더티 페이지를 파일의 적당한 위치에 랜덤 쓰기를 실행한다.
- 데이터 파일의 페이지들과 DoubleWirte 버퍼의 내용을 비교한다.
- 데이터 파일 페이지와 DoubleWirte 버퍼의 내용이 다르다면 DoubleWirte 버퍼의 내용을 데이터 파일의 페이지로 복사한다.
DoubleWirte 버퍼는 데이터의 안정성을 위해 자주 사용된다.
다만, SSD처럼 랜덤 IO 저장 시스템에서는 상당히 부담스러울 수 있으며 HDD처럼 자기 원판 순차 디스크 쓰기 저장 시스템에서 사용하기 덜 부담스럽다. 그럼에도 데이터의 무결성이 매우 중요하다면 DoubleWirte를 활성화하는 것이 좋다.
'BackEnd > Real MySQL 8.0' 카테고리의 다른 글
| [Real MySQL 8.0] 인덱스 살펴보기 1/2 (0) | 2022.06.23 |
|---|---|
| [Real MySQL 8.0] MySQL의 격리 수준 (0) | 2022.06.14 |
| [Real MySQL 8.0] 트랜잭션과 잠금 (0) | 2022.06.11 |
| [Real MySQL 8.0] InnoDB 스토리지 엔진 아키텍처 2/2 (0) | 2022.05.29 |
| [Real MySQL 8.0] MySQL 엔진 아키텍처 (0) | 2022.05.18 |