
[대규모 시스템 설계] 규모 확장에 따른 시스템 구성 이해하기
가상 면접 사례로 배우는 대규모 시스템 설계 기초 요약정리 글입니다.
한 명의 사용자를 지원하는 시스템에서부터 수 백만 사용자를 지원하는 시스템을 만드는 방법을 알아보기 앞서
기본적으로 사용자의 요청이 처리되는 과정을 이해할 필요가 있다.
다음은 가장 단순한 단일 서버에서 사용자의 요청이 처리되는 과정을 나타낸다.
사용자의 요청이 처리되는 과정

- 사용자가 웹 브라우저에 URL을 입력한다.
- 입력된 URL 정보는 DNS에서 IP 주소로 변환되어 반환된다.
- 반환된 IP 주소를 가진 웹 서버로 HTTP 요청이 전달된다.
- 요청받은 웹 서버는 HTML 페이지나 JSON 형태의 응답을 반환한다.
사용자 수에 따른 시스템 설계
만약 단 한 명의 사용자만 이용하는 시스템이라면 위와 같이 웹 앱, 데이터베이스, 캐시 등을 한 대의 서버
즉, 단일 서버에서 실행해도 아무 문제가 없다.
하지만 위와 같은 시스템은 트래픽이 증가하고 서버의 리소스가 부족해지면 아주 쉽게 망가질 수 있다.
이때 생각해볼 수 있는 해결 방법은 여러 서버를 두어 하나는 웹 / 앱 트래픽 처리 용도로 사용하고 다른 하나는 데이터베이스용으로 사용하는 것이다.
이렇게 서버를 분리하면 웹 계층과 데이터 계층이 분리되어 각각을 독립적으로 확장해 나갈 수 있게 된다.
수직적 규모 확장(scale up)과 수평적 규모 확장(scale out)
- 수직적 규모 확장(scale up)
- 수직적 규모 확장은 서버에 더 좋은 CPU, 더 많은 RAM 등을 추가하는 방법을 말한다.
- 수평적 규모 확장(scale out)
- 더 많은 서버를 추가해 성능을 개선하는 방법을 말한다.
수직적 확장은 아주 단순한 개념이기 때문에 적은 트래픽이 발생하는 경우 좋은 방법이 될 수도 있다.
하지만 불행히도 이 방법에는 몇 가지 심각한 단점이 있다.
첫째, 하드웨어의 특성상 고사양 자원을 무한대로 증설할 방법이 존재하지 않는다.
둘째, 장애에 대한 대응 즉, 다중화나 자동복구에 대한 방안이 없어 서버 장애 발생 시 웹/앱이 완전히 중단된다.
이러한 단점 때문에 대규모 시스템을 구성할 때는 수평적 규모 확장(scale out)이 적절하다.
로드밸런서
로드밸런서는 부하 분산 집합에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 한다.
하나의 웹 서버에 너무 많은 사용자가 몰리게 되면 응답 속도가 느려지거나 접속이 불가능해질 수 있다.
이런 경우 수평적 규모 확장으로 웹 서버를 늘리고 로드밸런서를 도입해 적절히 트래픽 부하를 분산시켜 문제를 해결할 수 있다.
이처럼 로드밸런서의 트래픽 부하 분산을 통해 웹 계층의 가용성을 향상시킬 수 있다.
가용성 향상의 구체적 예를 살펴보면 다음과 같다.
- 서버 1에 장애가 발생하더라도 로드밸런서를 통해 모든 트래픽을 서버 2로 넘겨줄 수 있다.
따라서 서비스 전체에 장애가 발생하는 일을 막을 수 있다. - 트래픽의 증가로 인해 서버 리소스가 부족하다면 웹 서버를 scale out 하기만 하면 된다.
이렇게 하면 로드밸런서가 자동으로 트래픽을 분산시켜준다.
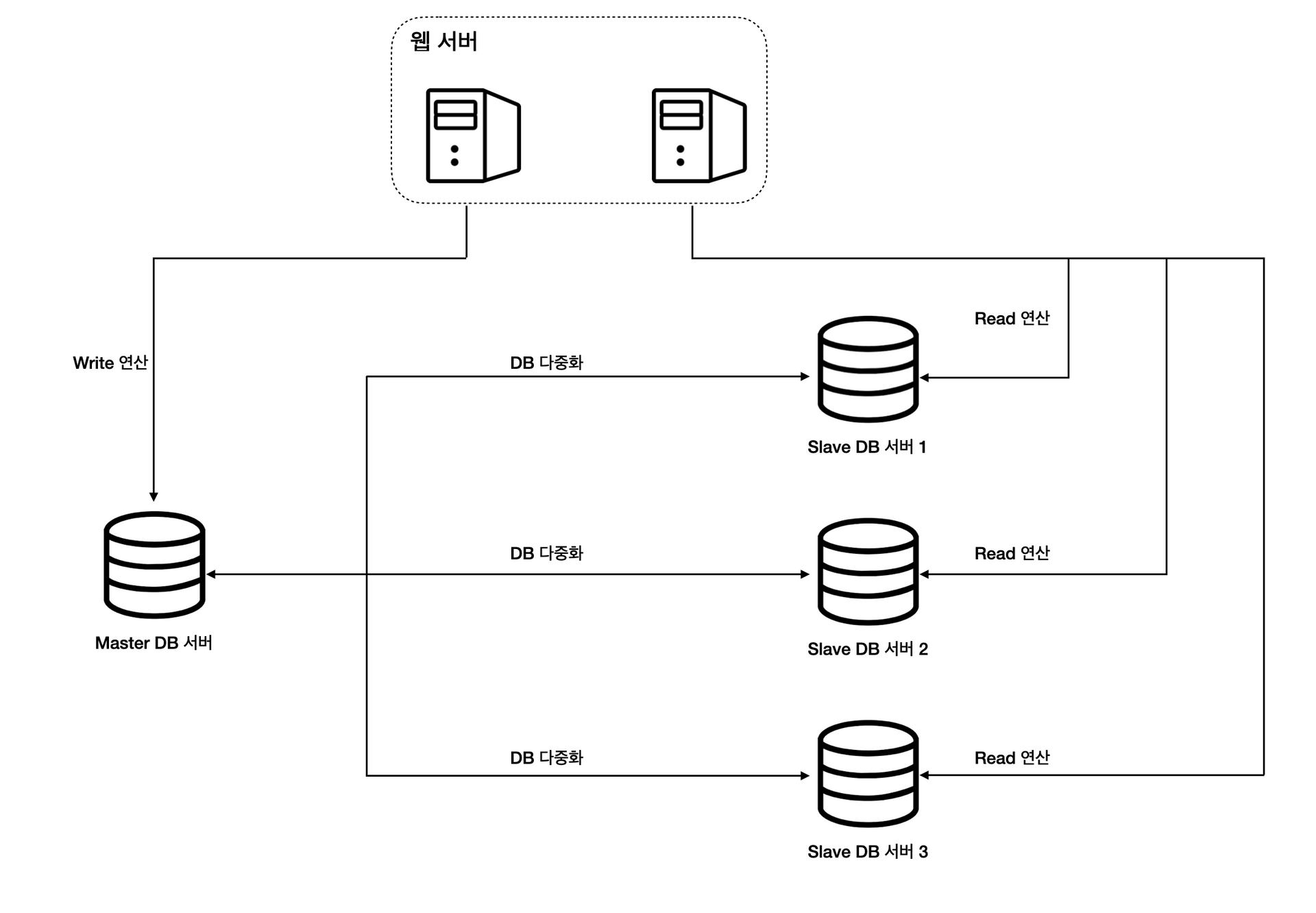
데이터베이스 다중화
위 그림처럼 서버를 구성하면 웹 계층의 부하는 잘 분산되지만 데이터 계층에 걸리는 부하는 그대로일 것이다.
여러 대의 서버가 하나의 데이터베이스로 READ / WRITE 요청을 보내기 때문이다.
이런 경우 데이터 계층에는 데이터베이스 다중화를 통해 장애나 부하 문제를 해결할 수 있다.
데이터베이스 다중화란 서버 사이에 master - slave 관계를 설정하고 데이터 원본은 master에, 사본은 slave에 저장하는 방식이다.
- 주(master) 서버의 역할
- write 연산
- 데이터의 원본을 가짐
- 부(slave) 서버의 역할
- read 연산
- master의 데이터베이스로부터 사본을 전달받아 저장
대부분의 애플리케이션은 쓰기 연산보다 읽기 연산의 비중이 훨씬 크기 때문에 일반적으로 부(slave) 데이터베이스를 더 많이 구성한다.
그렇다면 데이터베이스 다중화로 얻을 수 있는 이점은 어떤 것들이 있을까?
바로 더 나은 성능과 안정성, 가용성 등을 말할 수 있다.
성능
- write / update와 같은 데이터 변경 연산은 master로 read 연산은 slave로 분산되므로 병렬 처리될 수 있는 쿼리가 늘어나므로 성능이 좋아진다.
안정성
- 데이터베이스 서버를 물리적으로 떨어트려 다중화할 수 있으므로 그중 일부가 파손되어도 데이터는 안전하게 보존된다.
가용성
- 데이터를 여러 slave 서버에 복제해 둠으로써, 하나의 데이터베이스 서버에서 장애가 발생해도 다른 서버의 데이터를 가져와 계속 서비스할 수 있다.
만약 master 서버에 장애가 발생해 wirte 연산을 할 수 없는 상황이라면, slave 서버가 새로운 master 서버가 되고 write 연산을 이어가게 된다.
실제 운영 환경에서는 slave가 최신 상태가 아닐 수 있기 때문에 복구 스크립트로 구멍 난 데이터를 채워줘야 할 수도 있다. 이런 문제를 해결하기 위해선 다중 마스터나 원형 다중화 방식을 생각해볼 수 있다.
시스템 구성하기
앞서 살펴본 로드밸런서와 데이터베이스 다중화를 고려해 시스템을 다시 설계하면 다음과 같이 나타낼 수 있다.
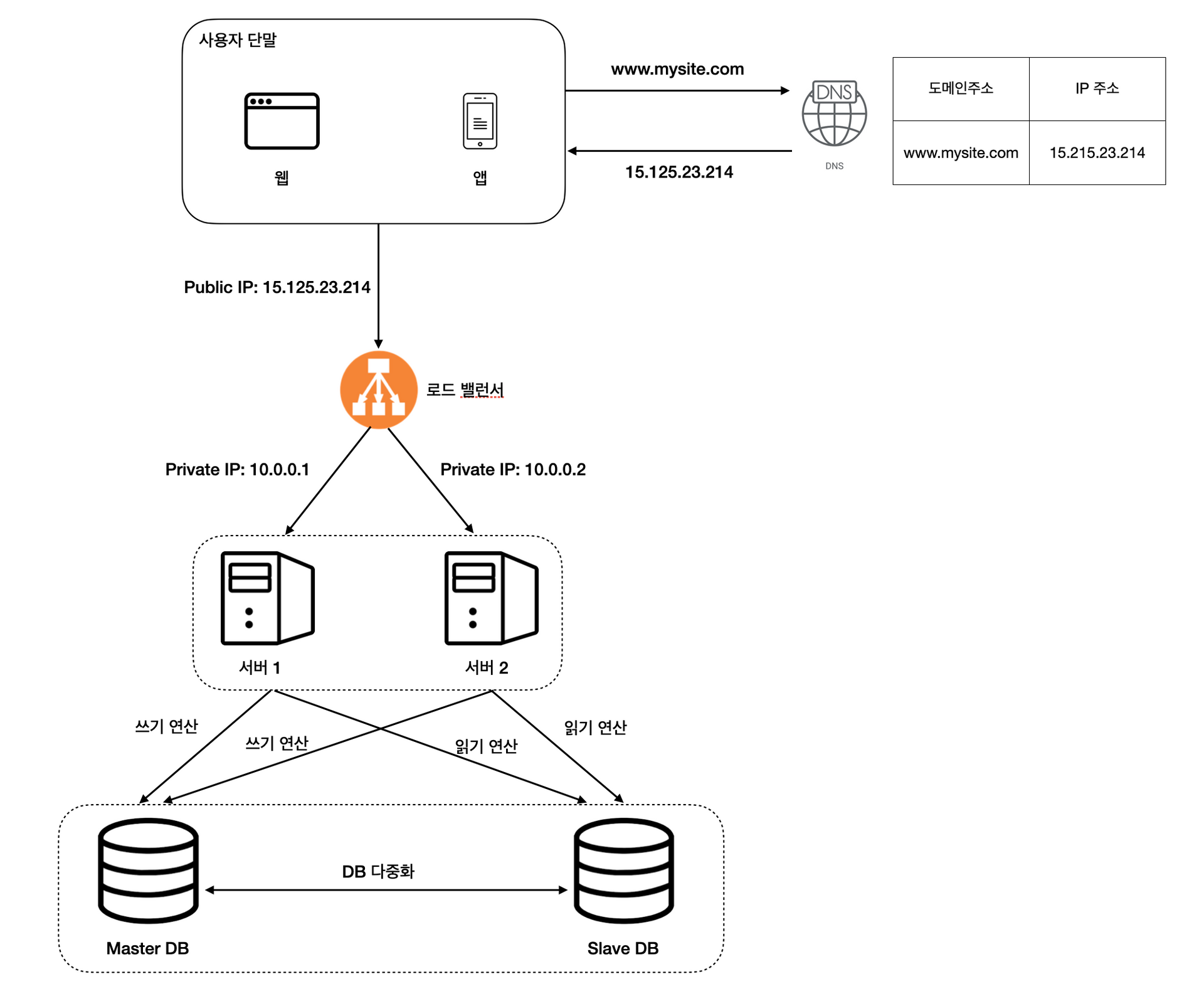
이 시스템의 동작 방식은 다음과 같다.
- 사용자가 웹 브라우저에 URL을 입력한다.
- 입력된 URL 정보는 DNS에서 IP 주소로 변환되어 반환된다.
- 반환된 IP 주소를 가진 로드밸런서에 접속한다.
- HTTP 요청은 로드밸런서에 의해 서버 1 혹은 서버 2로 전달된다.
- 웹 서버는 데이터를 Slave DB에서 읽어와 반환한다. 데이터 변경 연산(Create, Update, Delete)의 경우 Master DB로 전달된다.